Puppet Internals
Puppet内部原理
本文档目标是描述Puppet的 manifest在系统上是如何工作。此过程相当复杂,但是一般也不需要了解其中太多的细节。整理此文档也正是为了那些想了解更多关于Puppet内部机制人更方便更直接理解。
在介绍之前,我们先看两个关于Puppet的经典图。一方面希望这两幅图能帮助理解,另一方面也希望下面的解释能帮助理解这两幅图。
Puppet架构图
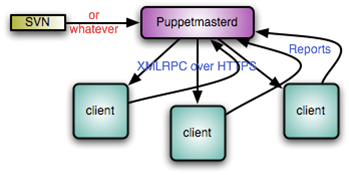
Puppet工作流程图
High Level
粗略来看,Puppet有三个主要的执行阶段--编译、实例化和配置
编译
这阶段描述如何将一个基于文本的manifest转变为一个针对特定节点规范(node-specific specification)。任何与此主机无关的代码都会被忽略,而任何与此主机相关的代码都会被插入,意味着变量扩展并且所有的结果都是文字字符串。
编译阶段与Puppet库资源类型的唯一联系就是所有作为结果的资源规范都会被验证:也就是验证指定的类型是有效的并且该类型所有特定属性都是有效的。这时候没有对属性值的验证。
在网络安装环境中,这阶段完全发生在服务端。此阶段的输出是一个类似于哈希的简单资源集合。
实例化
这阶段将简单的哈希和数组(编译阶段的输出)转变为Puppet库对象。因为这阶段需要依赖客户端的很多信息才能正常工作(比如,使用什么类型的包,什么类型的服务等),这阶段完全发生在客户端。
从简单的格式转换为文字的Puppet对象允许这些对象对输入做更强大的验证,这是大部分输入验证发生的地方。如果你指定有效的属性但却赋予无效的值,在这里你可以发现它。意味着你将在客户端实例化配置时验证这类值错误,而不是在服务端。
这阶段的输出是全部的机器配置,而它能够改变本地系统。
配置
这阶段Puppet真正改变系统。每个资源实例比较自身特定状态与机器状态并且去做任何需要更改的变动。如果机器状态恰好与指定状态一致,则不需要做任何变动。
Lower Level
上述三个阶段每个都可以分解为更多步骤。
编译阶段1:解析
输入:使用Puppet语言编写的Manifests
输出:解析树(AST对象实例)
入口:Puppet::Parser::Parser#parse
这时候,所有Puppet manifests开始为文本文件,解析器的工作就是理解这些文件。解析器只做了很少的工作-它将文本转换为一种文本直接映射回文本的格式,创建解析树本质上等价于(创建)文本自身。这时的验证仅仅是语法的验证。
这阶段无论是否使用节点,无论使用stand-alone Puppet解释器或者客户端/服务端系统。一旦启动Puppet,解析过程就会发生。
编译阶段2:解释
输入:解析树(AST对象实例)和客户端信息(由Facter收集的facts)
输出:Trees of TransObject and TransBucket instances
入口:Puppet::Parser::AST#evaluate
出口:Puppet::Parser::Scope#to_trans
许多配置需要依赖客户端信息来决定。当Puppet客户端开始运行,它会加载Facter库,收集所有能够收集的facts,并且将这些facts传给解释器。当你通过网络使用Puppet,这些facts会经过网络传输到服务端,然后服务端会利用这些信息来编译客户端配置。
这阶段传递给服务端的信息(像操作系统和硬件体系结构等),既让服务端能够对客户端配置做出决定,同时它也能让服务端向配置中插入客户端信息,像IP地址和MAC地址这些信息。
解释器将解析树和客户端信息合并为一个简单可传输对象树。这个可传输对象映射manifeasts定义的配置,它仍是一个树,但是它是一个类树,而资源包含在这些类中。
节点和无节点
当你使用Puppet时,有选项选择是否使用节点资源。如果不使用节点资源,每次一个客户端连接都需要解释整个配置,自顶向下解释解析树。在这种情况下,你必须有某种明确的选择机制来指定哪个代码适用哪个节点。
如果你使用节点资源,那么,解释器就会预编译所有与特定节点无关的代码。当一个节点连接时,解释器就会寻找此节点名(从Facter facts中检索)相关的代码然后仅仅编译这些相关代码。
配置传输
输入:可传输对象
输出:可传输对象
入口:Puppet::Network::Server::Master#getconfig
出口:Puppet::Network::Client::Master#getconfig
如果使用stand-alone Puppet,那么就没有配置传输,因为客户端和服务端是同一进程。如果使用基于网络的Puppetd客户端和Puppetmasterd服务端,那么这些配置一旦编译完毕,就必须发送到客户端。
Puppet目前是将这些可传输对象转变为YAML,它经过CGI转义然后使用XMLRPC通过HTTPS发送。客户端接收配置,反转义,缓存到磁盘以免下次服务端不可用,然后使用YAML再将它转换为普通ruby可传输对象。
实例化阶段
输入:可传输对象
输出: Puppet::Type instances
入口:Puppet::Network::Client::Master#run
出口:Puppet::Transaction#initialize
为了创建Puppet 库对象(Puppet::Type子类实例),在可传输对象顶层调用to_trans。所有的容器对象转换为Puppet::Type::Component实例,所有普通对象转变为Puppet资源类型实例。
这是所有输入验证发生地而且经常在这里值转换为更可用形式。例如,文件系统始终返回用户IDs,而不是用户名,因此Puppet对象将它们适当转换。(顺便提及下,有时候Puppet会在对文件chown时创建用户,意味着只要有可能Puppet会忽略验证错误直到最后一刻)。
一旦所有资源建立在一个类似图的组件和资源树时,这个树转变为一个GRATR图像。然后这个图像传递给一个新的事务实例。
配置阶段
输入:GRATR图
输出:事物报告
入口:Puppet::Transaction#evaluate
出口:Puppet::Transaction#generate_report
在这个阶段,所有工作的完成,由一个事务控制。
资源生成
一些资源管理其他资源实例,例如递归文件操作。在这个阶段,任何静态生成的资源都被生成。然后这些生成的资源被添加到资源图。
关系
配置进程的下一阶段创建一个图来为资源依赖建模。Puppet语言的目标之一就是使文件顺序问题尽可能少;这意味着一个需要依赖其他资源的Puppet资源在manifest中会被列在它依赖的资源之后,也就是说被依赖的资源将会在它依赖的资源之后被实例化。最后依赖关系图会和原始资源图进行合并来创建一个完整的有着所有资源和所有关系的图。
评估
配置事务会对最终关系图做一个拓扑排序并且遍历结果列表,按顺序评价每个资源。每个资源的每个非同步属性都会生成一个Puppet::StateChange对象。事务使用该对象严格控制这些资源需要做哪些改变和在什么时候改变,当然也会确保提供日志。
报告 随着事务的进行,它会收集日志和度量指标。在评估的最后,将这些信息转变为报告,发送给服务端。
总结
这是Puppet Manifest转变为一个完整配置的完整流程。对于Puppet系统,还有更多,例如FileBuckets,但是这些更多是支持角色而不是主要魅力所在。
blog comments powered by Disqus