Zabbix Performance Tunning
Zabbix高性能
这篇文章主要是由多篇文章整理而成。包括过去很多人使用总结出来的经验以及补充一些官方博客关于原理性的介绍。包括性能指标,性能优化和具体优化策略等内容。
性能概述
性能指标
- 指标一:NVPS
NVPS--通过Zabbix的NVPS(每秒处理数值数)来衡量其性能。 在Zabbix的dashboard上有一个粗略的估值。
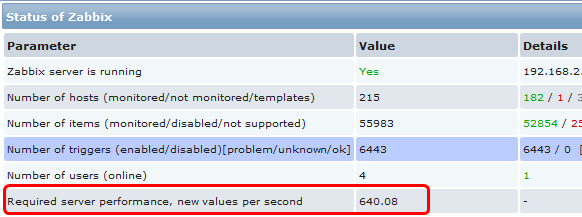
- 指标二:UP
UP--统计最近一小时内,数据更新的百分比--Update Percent[参考PPTV]
影响性能因素
| 因素 | 慢 | 快 |
| 数据库大小 | 巨大 | 适应内存大小 |
| 触发器表达式的复杂度 | min(),max(),avg() | last(),nodata() |
| 数据收集方法 | Polling(SNMP,No Proxy,被动式Agent) | Trapping(主动式Agent) |
| 数据类型 | 文本,字符串 | 数值 |
1. 监控项类型,值类型,SNMPv3,触发器数量和触发器类型
2. Housekeeper 设置
3. 数据库大小
4. 前端用户数量
5. 触发器复杂性
6. 监控主机数量
性能优化
优化原则
1. 监控 zabbix 内部组件
2. 各角色使用独立服务器且服务器硬件性能足够好
3. 使用分布式部署
4. 优化 zabbix 配置
5. 优化数据库性能
6. 关闭 Housekeeper,使用分区表
下面分别就数据库,Zabbix自身以及前端三方面介绍常见的优化。
数据库优化
这里大多数建议同样适用于很多应用程序,但是现在将围绕 Zabbix 来谈。
- 1.使用专用数据库服务器
数据库是 Zabbix 的重要瓶颈。尝试使用专用数据库服务器并确保其拥有很好的性能 (CPU,内存和快速磁盘读写)
2.单个文件创建单个数据库表
配置项: innodb_file_per_table=1
默认情况下,innodb 将在一个数据文件中创建所有的数据库表。通过这个选项, 新的数据库表会有自己的数据文件。因此更改后,你将需要重新创建数据库表。这个 选项也使比如将你的数据库表存储在不同的文件系统上以及让备份更具一致性成为可 能。它也可以有效解决单个表空间过大和表空间崩溃丢失数据问题。
对于使用这个选项后旧表的转化问题,使用脚本如下。对于像 history和 trends 这样的大表需要时间转化。需要定期的'优化'才能保证每个文件一个表。
Select concat('alter table ',TABLE_SCHEMA ,'.',table_name,' ENGINE=InnoDB;') FROM INFORMATION_SCHEMA.tables where table_type='BASE TABLE' and engine = 'InnoDB';
- 3.使用分区表并且禁用 HouseKeeper
HouseKeeper降低了MySQL 的性能,因此一个简单的替代就是使用MySQL 分区本地资源。
Zabbix 的每个监控项都会拥有自己的housekeeper 值,正是这个特点使得进程 housekeeping成为性能杀手,因为delete_history()函数在每个监控项每次运行时都会执行DELETE。如果你有100k的监控项,就会执行100K的DELETE 查询。尤其是对于innode引擎,问题将会很严重,因为对于大表的DELELTE 非常慢而且删除行并不能释放磁盘空间。所以建议禁用housekeeper并对表进行分区。
在考察Zabbix数据库表的时候,能很明显的看到history表特别大,这往往是瓶颈,需要进行分区。最后附上创建分区表的方法,基于时间戳的分区。
- 4. 临时文件使用 tmpfs 文件系统
使用内存代替磁盘将允许 MySQL 更快速创建临时表。首先,创建挂载点:
mkdir /tmp/mysqltmp
然后在/etc/fstab 文件中加入以下内容:
tmpfs /tmp/mysqltmp tmpfs rw,uid=mysql,gid=mysql,size=1G,nr_inodes=10k,mode=0700 0
对于size参数,最好是使用物理内存的 8%至 10% 最后需要在配置文件/etc/my.cnf 中定义路径并重启 MySQL:
tmpdir = /tmp/mysqltmp
- 5. 设置合理 buffer/pool
这是/etc/my.cnf 中最重要的参数之一,它定义了 innodb 能够使用多少内存。建议使用物理内存的 70%至 80%。同时设置 innodb 使用 O_DIRECT 这样缓存在 innodb buffer pool 中的数据就不会复制到文件系统的 buffer cache,并且降低 swap 压力,但 须小心没有电池备份 RAID 的情况。具体配置如下:
innodb_buffer_pool_size=14G
innodb_flush_method = O_DIRECT
还有很多优化策略同其他数据库类优化类似,比如很多针对Innodb的优化,针对业务场景的优化等等。其他优化包括但不限于:
其他参数
打开慢查询日志:logslowqueries=/var/log/mysql.slow.log
其他MySQL参数优化同一般性优化措施。包括但不限于:
thread_cache_size=4 这个值似乎会影响show global status输出中Threads_created per Connection的hit rate
query_cache_limit=1M
query_cache_size=128M
tmp_table_size=256M
max_heap_table_size=256M
table_cache=256
这些同样根据其他的优化文档,但是基于zabbix数据库的表数量(zabbix数据库共有73个表加上临时表和mysql表)证明还是比较合适的。
innnodb_flush_log_at_trx_commit=2
对于不是关心严格的ACID时,这个参数对于大量写会比较好
join_buffer_size=256K
read_buffer_size=256K
read_rnd_buffer_size=256K
Zabbix 优化
关于Zabbix的优化主要涉及如何进行Zabbix配置进行参数调优,在介绍优化之前,先介绍为什么要调整这些参数,这些参数在Zabbix内部有什么作用。
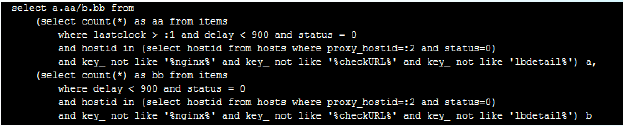
背景介绍:如何监测Zabbix是否繁忙
在过去,Zabbix用户经常会被一些服务器优化参数所迷惑。例如,需要多少Pollers。经常是根据经验来决定,再测试一系列猜测。自从zabbix1.8.5之后,再也不用这些模糊的尝试。这个版本增加的新特性将这些都技巧性的完美展现出来了。
应该需要多少Pollers?
常见的问题就是对于这些数量可配置的多种zabbix进程如何决定它们的进程数量。例如,默认情况下zabbix server开启5个Pollers进程。这对于小型安装已经足够了,但是当监控100主机?1000主机?10000主机?然后就必须考虑根据使用的监控协议,监控设备的性能,网络和其他很多东西,对于这些不同环境需要不同的进程数量。
在大多数情况下,不仅仅只有这一件事需要考虑,其他所有数量可配置的进程都需要考虑。例如,Trappers处理进来的连接(incoming connections),特定类型的Pollers,像HTTP类型,它用来运行WEB监控情景等等。
内部监控项
伴随着这么多数量不确定,新特性的到来真的是很方便-新特定就是内部监控项。作为所有的内部监控项,它们的key都是zabbix。根据zabbix手册,所有的key和它的语法如下:
* zabbix[process,<type>,<mode>,<state>]
我们能看到第一个参数就是关键字process,下面来看看其他参数。
可用的状态(states)
先来看最后一个参数state。目前只支持两种状态:
繁忙--busy
空闲--idle
很简单的两种状态,因此我们能够监控多少时间(百分比形式)某个个活动是繁忙的还是空闲的,这里繁忙意味着做什么事都需要等待,比如通过网络连接到某设备,查询某些监控项来进行核对或者其他。现在还没有能对这些活动进行区别的功能,或许以后会出现。
可用的模式(modes)
对于监控集中不同的事件也是可能,这通过mode参数控制。
监控特定类型的所有进程
或者这是最常见的使用情况,监控某种类型的所有进程(像所有的Pollers或Trappers)。这种情况下,mode可以是:
avg -- 特定类型所有进程的平均值。这是默认值
max--所有进程的最大值
min--所有进程的最小值
因此如果有5个Pollers进程是繁忙的,每个分别是5%,10%,15%,20%和25%的时间需要休息,那么最小值模式的值是5,最大值模式的值是25,平均值模式的值是15
被计算的值只能是过去一分钟的数据,因此要拥有合理正确的值就需要将监控项的更新间隔设置为60秒
监控某个特定的进程
当然也可以监控某个单独的进程。在这种情况下,mode就是这个进程的进程号码。这个号码是由开启进程的个数按照顺序从1依次递增的。依次如果你有5个Pollers进程,进程号码就会从1至5。要对这5个进程进行单独监控,就需要创建5个单独的监控项。
这样的优点就是能够查看到某个事件的更详细的信息。例如,如果某个Pollers因为某种原因处于100%繁忙的状态,而其他四个都是彻底的空闲态,对所有的平均值就会显示是20%繁忙,这会被认为很正常。但是在另一方面,看到一个进程完全繁忙而其余什么都不做完全空闲就一定会让人调查这个情景。当然,这明显意味着多些配置少些数据收集。
监控多个进程
最后需要考虑的模式是-count。这仅仅是提供特定类型的进程数量。当然,这时我们不在指定任何状态,大量进程无法判断是繁忙还是空闲。
可用的进程类型(types)
这个参数指定监控的进程类型。zabbix server拥有多种不同类型的进程。实际上在1.8.5版本中共有17种。这些进程对不同的事件进行不同的处理,如果你在zabbix server启动后查看日志文件就会看到类似以下的内容:
server #11 started [Trapper]
server #12 started [Trapper]
server #13 started [ICMP pinger]
server #0 started [Watchdog]
server #14 started [Alerter]
server #15 started [Housekeeper]
工作进程数量优化参考zabbix_server.conf:
StartPollers=90
StartPingers=10
StartPollersUnreacheable=80
StartIPMIPollers=10
StartTrappers=20
StartDBSyncers=8
LogSlowQueries=1000
前端加速
常见方法有使用 GZIP 压缩,对于 PHP 可用 eAccelerator。更多前端优化可参考雅虎前端优化法则。
参考资料
http://www.slideshare.net/xsbr/alexei-vladishev-zabbixperformancetuning
http://zabbixzone.com/zabbix/mysql-performance-tips-for-zabbix/
http://blog.zabbix.com/monitoring-how-busy-zabbix-processes-are/
http://linux-knowledgebase.com/en/Tip_of_the_day/March/Performance_Tuning_for_Zabbix
http://sysadminnotebook.blogspot.jp/2011/08/performance-tuning-mysql-for-zabbix.html
附录:基于时间戳的分区做法
step 1.准备相关表
ALTER TABLE `acknowledges` DROP PRIMARY KEY, ADD KEY `acknowledgedid` (`acknowledgeid`);
ALTER TABLE `alerts` DROP PRIMARY KEY, ADD KEY `alertid` (`alertid`);
ALTER TABLE `auditlog` DROP PRIMARY KEY, ADD KEY `auditid` (`auditid`);
ALTER TABLE `events` DROP PRIMARY KEY, ADD KEY `eventid` (`eventid`);
ALTER TABLE `service_alarms` DROP PRIMARY KEY, ADD KEY `servicealarmid` (`servicealarmid`);
ALTER TABLE `history_log` DROP PRIMARY KEY, ADD PRIMARY KEY (`itemid`,`id`,`clock`);
ALTER TABLE `history_log` DROP KEY `history_log_2`;
ALTER TABLE `history_text` DROP PRIMARY KEY, ADD PRIMARY KEY (`itemid`,`id`,`clock`);
ALTER TABLE `history_text` DROP KEY `history_text_2`;
step2.设置每月的分区
以下步骤请在第一步的所有表中重复,下例是为events表创建2011-5到2011-12之间的月度分区。
ALTER TABLE `events` PARTITION BY RANGE( clock ) (
PARTITION p201105 VALUES LESS THAN (UNIX_TIMESTAMP("2011-06-01 00:00:00")),
PARTITION p201106 VALUES LESS THAN (UNIX_TIMESTAMP("2011-07-01 00:00:00")),
PARTITION p201107 VALUES LESS THAN (UNIX_TIMESTAMP("2011-08-01 00:00:00")),
PARTITION p201108 VALUES LESS THAN (UNIX_TIMESTAMP("2011-09-01 00:00:00")),
PARTITION p201109 VALUES LESS THAN (UNIX_TIMESTAMP("2011-10-01 00:00:00")),
PARTITION p201110 VALUES LESS THAN (UNIX_TIMESTAMP("2011-11-01 00:00:00")),
PARTITION p201111 VALUES LESS THAN (UNIX_TIMESTAMP("2011-12-01 00:00:00")),
PARTITION p201112 VALUES LESS THAN (UNIX_TIMESTAMP("2012-01-01 00:00:00"))
);
step3.设置每日的分区
以下步骤请在第一步的所有表中重复,下例是为history_uint表创建5.15到5.22之间的每日分区。
ALTER TABLE `history_uint` PARTITION BY RANGE( clock ) (
PARTITION p20110515 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-16 00:00:00")),
PARTITION p20110516 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-17 00:00:00")),
PARTITION p20110517 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-18 00:00:00")),
PARTITION p20110518 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-19 00:00:00")),
PARTITION p20110519 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-20 00:00:00")),
PARTITION p20110520 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-21 00:00:00")),
PARTITION p20110521 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-22 00:00:00")),
PARTITION p20110522 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-23 00:00:00"))
);
手动维护分区:
增加新分区
ALTER TABLE `history_uint` ADD PARTITION (
PARTITION p20110523 VALUES LESS THAN (UNIX_TIMESTAMP("2011-05-24 00:00:00"))
);
删除分区(使用Housekeepeing)
ALTER TABLE `history_uint` DROP PARTITION p20110515;
step4.自动每日分区
确认已经在step3的时候为history表正确创建了分区。
以下脚本自动drop和创建每日分区,默认只保留最近3天,如果你需要更多天的,请修改@mindays 这个变量。
不要忘记将这条命令加入到你的cron中!
mysql -B -h localhost -u zabbix -pPASSWORD zabbix -e "CALL create_zabbix_partitions();"
blog comments powered by Disqus