深入理解Linux内核中断及其特性(更新)
摘要
本文对中断系统进行详细的剖析,主要内容包括中断与异常、中断实现、中断控制器、中断上下文、中断亲和力和中断线程化等。 首先简单介绍 Linux 内核中断常用概念及其本质,然后对中断实现基本原理进行简要分析,接着详细探讨了中断亲和力的实现原理,最后对中断线程化背景及工作原理进行介绍。
关键字: 中断,中断控制器,中断上下文,中断亲和力,中断线程化
什么是中断
对于中断的理解我们先看一个生活中常见的例子:QQ。第一种情况:你正在工作,然后你的好友突然给你发送了一个窗口抖动,打断你正在进行的工作。第二种情况:当然你有时候也会每隔 5 分钟就去检查一下 QQ 看有没有好友找你,虽然这很浪费你的时间。在这里,一次窗口抖动就可以被相当于硬件的中断,而你就相当于 CPU,你的工作就是 CPU 这在执行的进程。而定时查询就被相当于 CPU 的轮询。在这里可以看到:同样作为 CPU 和硬件沟通的方式,中断是硬件主动的方式,较轮询(CPU 主动)更有效些,因为我们都不可能一直无聊到每隔几分钟就去查一遍好友列表。
CPU 有大量的工作需要处理,更不会做这些大量无用功。当然这只是一般情况下。好了,这里又有了一个问题,每个硬件设备都中断,那么如何区分不同硬件呢?不同设备同时中断如何知道哪个中断是来自硬盘、哪个来自网卡呢?这个很容易,不是每个 QQ 号码都不相同吗?同样的,系统上的每个硬件设备都会被分配一个 IRQ 号,通过这个唯一的 IRQ 号就能区别张三和李四了。
中断的本质是一种电信号(物理学),由硬件产生,并直接送往中断控制器的输入引脚中—中断控制器是一个简单的电子芯片。当接收到一个中断后,中断控制器会给处理器发送一个电信号。处理器一经检测到此信号,便中断自己当前工作转而处理中断。此后,处理器会通知操作系统已经产生中断,这样,操作系统就可以对这个中断进行适当的处理。接下来,我们通过几组概念来了解中断的基本概貌。
中断与异常
在操作系统中,讨论中断就不能不提及异常。异常与中断不同,它在产生时必须考虑处理器同步。
关于异常与中断的区别,总结有一句话:中断时由硬件产生的异步中断,而异常则是处理器产生的同步中断。所谓同步是指只有在一条指令执行完毕后 CPU 才会发出中断,而不是发生在代码指令执行期间,比如系统调用。而异步就是中断能够在指令之间发生。它们之间处理方式类似。
| 类别 | 原因 | 异步/同步 | 返回行为 |
| 中断 | 来自IO设备的信号 | 异步 | 总是返回到下一条指令 |
| 陷阱 | 有意的异常 | 同步 | 总是返回到下一条指令 |
| 故障 | 潜在可恢复的错误 | 同步 | 返回当前指令 |
| 终止 | 不可恢复的错误 | 同步 | 不会返回 |
中断上下文与进程上下文
这些上下文代表着内核活动的范围。每个处理器在任何指定时间点上的活动必然概括为下列三者之一 : + 运行于用户空间,执行用户进程 + 运行于内核空间,执行进程上下文,代表某个特定的进程执行。 + 运行于内核空间,执行中断上下文,与任何进程无关,处理某个特定中断。
以上所列几乎包括所用情况,即使边边角角的情况也不例外。例如,CPU空闲,内核运行空进程,出于进程上下文,但运行于内核空间。
在进程上下文中可以通过 Current 宏相关联当前进程,进程上下文可以调用调度程序、可以睡眠。
而在中断上下文中,和进程无关、 current 宏无关,不能睡眠、和不能调用会导致睡眠的函数。中断上下文具有较为严格的时间限制,必须迅速而简洁。
上半部和下半部
在响应一个特定中断的时候,内核会执行一个函数,该函数叫做中断处理程序。产生中断的每个设备都有一个相应的中断处理程序,它和特定中断相关联我们又想中断处理程序运行得快,又想中断处理程序完成任务多,这两个目标抵触下,我们把中断处理程序切分为上半部和下半部。
上半部包括中断处理程序,一般处于中断上下文,还和特定体系结构相关。执行中断处理程序时,有可能需要禁止本地或全局中断,加上其异步执行特点,我们希望尽力缩短中断处理程序的执行,把一些工作放在以后执行。
在上半部,内核通过对它的异步执行完成对硬件中断的即时响应。快速、异步、简单的机制负责对硬件做出迅速响应并完成那些时间要求很严格的操作。而下半部完成推后执行的工作,执行与中断处理密切相关但中断处理程序本身并不执行的工作;稍后执行,而且执行期间可以响应所有的中断。
一个简单的上下半部分开的例子就是网卡:拷贝网络数据包到内存,然后读取网卡更多数据包一般在上半部执行,以免网卡缓存溢出。而处理和操作数据包的其他工作在下半部执行。下半部只是推后执行,并没有强调多久,只是不是马上立刻。
8259A与APIC(高级可编程中断控制器)
这是两种常见的中断控制器,先来看传统的8259A中断控制器:传统的 PIC(Programmable Interrupt Controller)是由两片 8259A 风格的外部芯片以“级联”的方式连接在一起。每个芯片可处理多达8个不同的 IRQ。因为从PIC的INT输出线连接到主PIC的IRQ2引脚,所以可用IRQ线的个数达到15个。
传统的 8259A 只适合单 CPU 的情况,现在都是多CPU多核的SMP体系,所以为了充分利用SMP体系结构、把中断传递给系统上的每个CPU以便更好实现并行和提高性能,Intel 引入了高级可编程中断控制器(APIC)。在SMP上,必须考虑外部设备来的中断信号如何传递给某个合适的CPU问题,必须考虑IPI(Inter-Percossor Interrupt,处理器间中断)问题。Intel自Pentium之后,在CPU中集成了APIC,在SMP上,主板上有一个(至少一个,有的主板有多个IO-APIC,用来更好的分发中断信号)全局的APIC,它负责从外设接收中断信号,再分发到CPU上,这个全局的APIC被称作IO-APIC。还有一部分是“本地 APIC”,主要负责传递中断信号到指定的处理器;举例来说,一台具有三个处理器的机器,则它必须相对的要有三个本地 APIC。
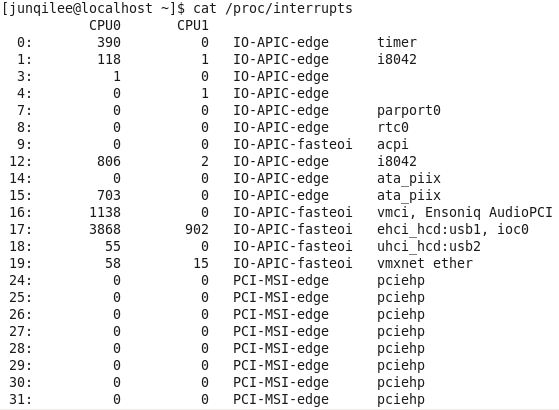
我们可以通过查看/proc/interrupts来判断是否使用APIC还是8259A。输出结果如图3:
Linux2.6中断原理介绍
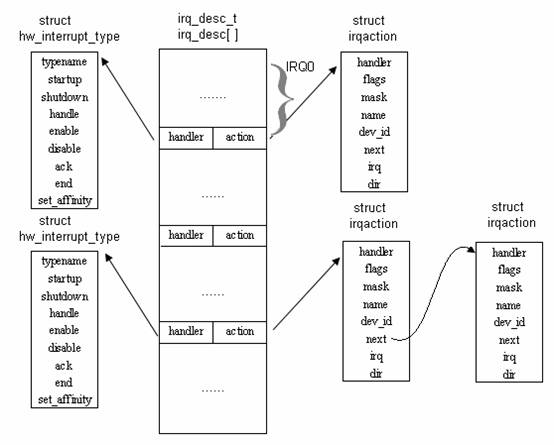
中断初始化阶段,调用hwinterrupttype类型的变量初始化irqdesct结构中的handle成员。再早期的系统中使用级联的8259A,所以将用i8259Airqtype来进行初始化,而对于SMP体系结构系统来说,以ioapicedgetype或ioapicleveltype来进行初始化handle变量。
对于每一个外设,要么以静态(声明为 static 类型的全局变量)或动态(调用 requestirq 函数)的方式向 Linux 内核注册中断处理程序。不管以何种方式注册,都会声明或分配一块 irqaction 结构(其中 handler 指向中断服务程序),然后调用 setupirq() 函数,将 irqdesct 和 irqaction 联系起来。
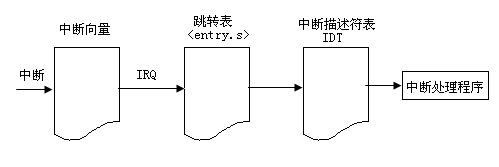
当中断发生时,通过中断描述符表 IDT 1获取中断服务程序入口地址,对于每条中断线,处理器会跳到对应的一个唯一地址。这样内核就知道所接收中断的IRQ号了。初始入口点只是在栈中保存这个号,并存放当前寄存器的值。随后内核将调用 doIRQ() 函数,以中断向量为 irqdesc[] 结构的下标,获取 action 的指针,然后调用 handler 所指向的中断服务程序。从以上描述,我们不难看出整个中断的流程,如图 5 所示:
中断亲和力
硬件中断发生频繁,是件很消耗CPU资源的事情,在多核CPU条件下如果有办法把大量硬件中断分配给不同的CPU (core)处理显然能很好的平衡性能。现在的服务器上动不动就是多CPU多核、多网卡、多硬盘,如果能让网卡中断独占1个CPU (core)、磁盘IO中断独占1个CPU的话将会大大减轻单一CPU的负担、提高整体处理效率。中断亲和力是指将一个或多个中断源绑定到特定的CPU上运行。
- 如何使用
在进行之前,我们先停掉 IRQ 自动调节的服务进程,这样才能手动绑定 IRQ 到不同 CPU,否则自己手动绑定做的更改将会被自动调节进程给覆盖掉。

我们还需要知道:在/proc/irq目录中,对于已经注册中断处理程序的硬件设备,都会在该目录下存在一个以该中断号命名的目录 IRQ# ,IRQ#目录下有一个 smp_affinity文件(SMP 体系结构才有该文件),它是一个CPU的位掩码,可以用来设置该中断的亲和力, 默认值为 0xffffffff,表明把中断发送到所有的CPU上去处理。
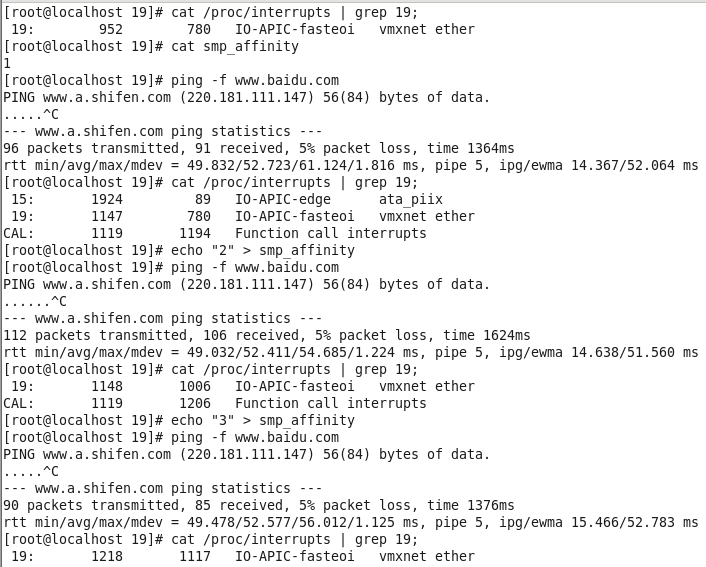
在这里,我们以网卡(我的实验机上网卡中断号为19)为例,虚拟机是两个CPU(每个单核)来设置中断亲和力。在/proc/interrupts中第二列和第三列分别是CPU0和CPU1上的中断次数。在这个例子中,我们可以看到随着对smp_affinity不同设置,在每个CPU上中断响应次数的变化。接下来我们将讲述具体绑定如何计算。
- 怎么计算
前面例子中我们已经看到smpaffinity的神奇了,我们曾提到,smpaffinity是CPU位掩码,那么它和具体CPU又是什么关系。其实这只是二进制数字而已。Echo “2” > smp_affinity中的2就是0x00000010。所以各个CPU用二进制和十六进制表示就是:
| CPU Number | Binary | Hex |
| CPU 0 | 00000001 | 1 |
| CPU 1 | 00000010 | 2 |
| CPU 2 | 00000100 | 4 |
| CPU 3 | 00001000 | 8 |
所以,当我们想把中断绑定到CPU0和CPU1上时,我们只需要echo “3” > smp_affinity即可。具体演示在上面示例中。需要注意的是,还是刚才说过的,就是在手动绑定IRQ到CPU之前需要先停掉irqbalance这个服务,irqbalance是个服务进程、是用来自动绑定和平衡IRQ的。
- 实现原理
上面讲述了中断亲和力的设置和具体机器中如何计算绑定到哪个CPU上。下面我们探讨中断亲和力实现原理。我们先看一下I/O APIC内部组成,它和中断亲和力设置密切相关。
I/O APIC 由一组 24 条 IRQ 线,一张 24 项的中断重定向表(Interrupt Redirection Table),可编程寄存器,以及通过 APIC 总线发送和接收 APIC 信息的一个信息单元组成。其中与中断亲和力息息相关的是中断重定向表,中断重定向表表中的每一项都可以被单独编程以指明中断向量和优先级、目标处理器及选择处理器的方式。这个重定向表很关键。
在系统初始化期间,对于 SMP 体系结构,将会调用 setupIOAPICirqs() 函数(arch/i386/kernel/ioapic.c)来初始化 I/O APIC芯片,芯片中的中断重定向表的24项被填充。在系统启动期间,所有的 CPU 都执行setuplocalAPIC()函数(arch/kernel/i386/apic.c),完成本地的APIC初始化。当有中断被触发时,将相应的中断重定向表中的值转换成一条消息,然后,通过 APIC 总线把消息发送给一个或多个本地APIC单元,这样,中断就能立即被传递给一个特定的 CPU,或一组CPU,或所有的CPU,从而来实现中断亲和力。
再来看一下,为什么我们传统的8259A芯片不行,而必须要I/O APIC才能实现。传统的i386处理器采用8259A中断控制器。一般而言,8259A的作用是提供多个外部中断源与单一CPU间的连接。如果在SMP结构中还是采用8259A中断控制器,就只能静态地把所有的外部中断源划分成若干组,分别把每一组都连接到一个8259A,而8259A则与CPU一对一连接,这样就达不到动态分配中断请求的目的。
- 有了中断亲和力,我们能干什么
经过调整,我们通过TOP观察到CPU使用率略有下降,Vmstat观察到CS次数也略有下降。虽然对系统性能的提升并不明显,但大致可以认为,相同中断尽量集中在同一个CPU Core可能有助于Cache Flush和CS次数。因为在我的个人笔记本上跟中断相关的进程CPU使用率不高,所以这些观察现象不明显。
在网络压力非常大的情况下,对于文件服务器、高流量 Web 服务器这样的应用来说,把不同的网卡IRQ均衡绑定到不同的CPU上将会减轻某个CPU的负担,提高多个CPU整体处理中断的能力;对于数据库服务器这样的应用来说,把磁盘控制器绑到一个CPU、把网卡绑定到另一个CPU将会提高数据库的响应时间、优化性能。合理的根据自己的生产环境和应用的特点来平衡IRQ中断有助于提高系统的整体吞吐能力和性能。
中断线程化
中断线程化是实现Linux实时性的一个重要步骤,在Linux标准内核中,中断时最高优先级的执行单元,不管内核代码当时处理什么,只要有中断事件,系统将立即响应改事件并执行相应的中断处理代码,除非当时中断禁用。因此,如果系统有严重的网络或I/O负载,中断将非常频繁,实时任务将很难有机会运行,也就是说毫无实时性可言。
- 应用背景
Linux实时性的要求,中断线程化之后,中断将作为内核线程运行而且赋予不同的实时优先级,实时任务可以有比中断线程更高的优先级,这样,实时任务就可以作为最高优先级的执行单元来运行,即使在严重负载下仍有实时性保证。
中断线程化的另一个重要原因是spinlock被mutex取代。中断处理代码中大量地使用了spinlock,当spinlock被mutex取代之后,中断处理代码就有可能因为得不到锁而需要被挂到等待队列上,但是只有可调度的进程才可以这么做,如果中断处理代码仍然使用原来的spinlock,则spinlock取代mutex的努力将大打折扣,因此为了满足这一要求,中断必须被线程化,包括IRQ和softirq。
- 实现原理
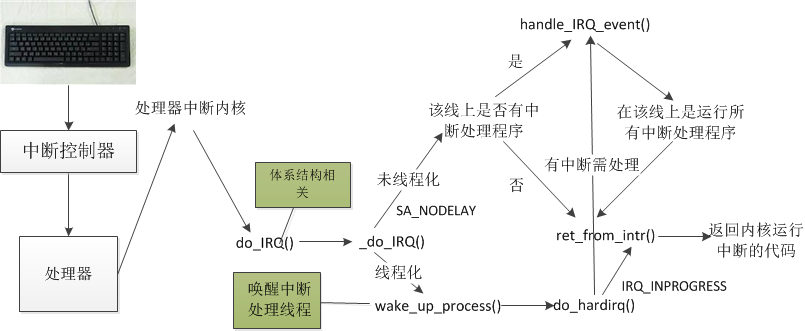
现在的线程化是作为内核R-T Patch实现的,并不是主流,是一个实时补丁。我们简单看一下其整个实现流程。[4][5]
中断初始化:对于向量表的初始化在系统引导时就已经开始了。通过调用setupidt将向量表中的每一项都初始化为默认的中断服务例程ignoreint。这个默认的例程只是打印中断向量号,因此需要进一步初始化;在调用startkernel()函数进行内核初始化时,将调用initIRQ()函数对中断进行第二次初始化,将IRQi对应的IDT表项设成interrupti,这部分已经运行于保护模式下。在startkernel结尾处调用我们的线程初始化函数inithardirqs,该函数为每个IRQ创建一个内核线程。最高实时优先级为50,依次类推直到25,因此任何IRQ 线程的最低实时优先级为25。
中断处理过程:如果某个中断号状态位中的 IRQNODELAY 被置位,那么该中断不能被线程化。在中断处理阶段,两者之间的异同点主要体现在:两者相同的部分是当发生中断时,CPU 将调用 doIRQ() 函数来处理相应的中断,doIRQ() 在做了必要的相关处理之后调用 _doIRQ()。两者最大的不同点体现在 doIRQ() 函数中,在该函数中,将判断该中断是否已经被线程化(如果中断描述符的状态字段不包含 IRQNODELAY 标志,则说明该中断被线程化了),对于没有线程化的中断,将直接调用 handleIRQ_event() 函数来处理。
对于已经线程化的情况,调用 wakeupprocess() 函数唤醒中断处理线程,并开始运行,内核线程将调用 dohardirq() 来处理相应的中断,该函数将判断是否有中断需要被处理,如果有就调用 handleIRQevent() 来处理。handleIRQ_event() 将直接调用相应的中断处理函数来完成中断处理。
- 线程化之后,我们还需要思考的问题
一旦中断线程化之后,中断将会运行在进程上下文中,而之前中断上下文所有的约束在这里将不复存在。我们也可以动态地对线程化的中断设置优先等级。那么,对于这种中断世界“革命性”的改变,我们又该有哪些思考:
还需要下半部吗?
中断线程化后,中断可以运行与进程上下文,没有了中断上下文的束缚。那么我们还需要下半部吗,因为在下半部能做的事情,现在都可以通过线程化中断实现了。作为我个人来看,并不认为这时候就可以草率的淘汰下半部。首先,中断线程化还需完善,还需标准化。现在只是作为一个补丁提供在内核中,还需考验。其次,中断线程化并不是万能的,我们很多事情是中断线程化不能实现的,后面会谈到。再者,下半部作为辅助中断处理程序来完成推后执行的工作,在一些场合下仍然具有不可替代的作用。
- 和CPU亲和力相结合
同中断亲和力一样,CPU也有亲和力,所谓CPU亲和力就是通过设置 CPU 亲和力(CPU affinity),将一个或多个进程绑定到一个或多个处理器上运行。一旦中断线程化后,中断就可以用进程(或线程)的观点来看待,这就为我们把中断线程化和CPU亲和力相结合提供可能。对于线程化的中断,我们可以通过设置CPU亲和力来限制线程迁移和优化处理器Cache使用率。当然可能的应用还有很多,这也是研究的方向。 线程化不一定永远好
并不是所有的中断都可以被线程化,比如时钟中断,主要用来维护系统时间以及定时器等,其中定时器是操作系统的脉搏,一旦被线程化,就有可能被挂起,这样后果将不堪设想,所以不应当被线程化。类似的还有串行端口等。所以即使现在我们能够线程化我们的中断并不意味着我们都应该线程化我们的中断。
总结
随着中断亲和力和中断线程化的相继实现,Linux 内核在SMP和实时性能方面的表现越来越让人满意,完全有理由相信,在不久的将来,中断线程化将被合并到基线版本中。中断亲和力将为Linux性能调优提供一个很好的选择,而中断线程化我们完全有理由相信将会发挥越来越重要的作用。也许很多系统将会被要求重新设计以充分利用线程化技术。
参考文献
- [1]Randal E.Bryant, David O Hallaron著.龚奕利,雷迎春译.深入理解计算机系统(修订版)[M].北京:中国电力出版社,2004.
- [2]Robert Love著.陈莉君,康华译.Linux内核设计与实现(原书第三版)[M].北京:机械工业出版社,2011.
- [3]http://www.ibm.com/developerworks/cn/linux/l-cn-linuxkernelint/ Linux中断内幕.苏春艳,杨小华.
- [4]王新政,程小辉,周华茂.实时操作系统任务调度策略的研究与设计[J].微计算机信息, 2007,(11).
- [5]金文学. Linux2.6内核实时技术研究与实现[D]. 中国科学院研究生院, 2008.
- [6]孙守昌,韩红芳,孟煜.嵌入式Linux实时技术改进与实现[J].嵌入式操作系统应用.2007.
blog comments powered by Disqus